Table of Contents
- The Enterprise AI Gold Rush Has Entered Its Reality Phase
- Key Findings From Enterprise AI Deployments
- The Most Common Failure Point: Treating AI as a Feature Instead of a System
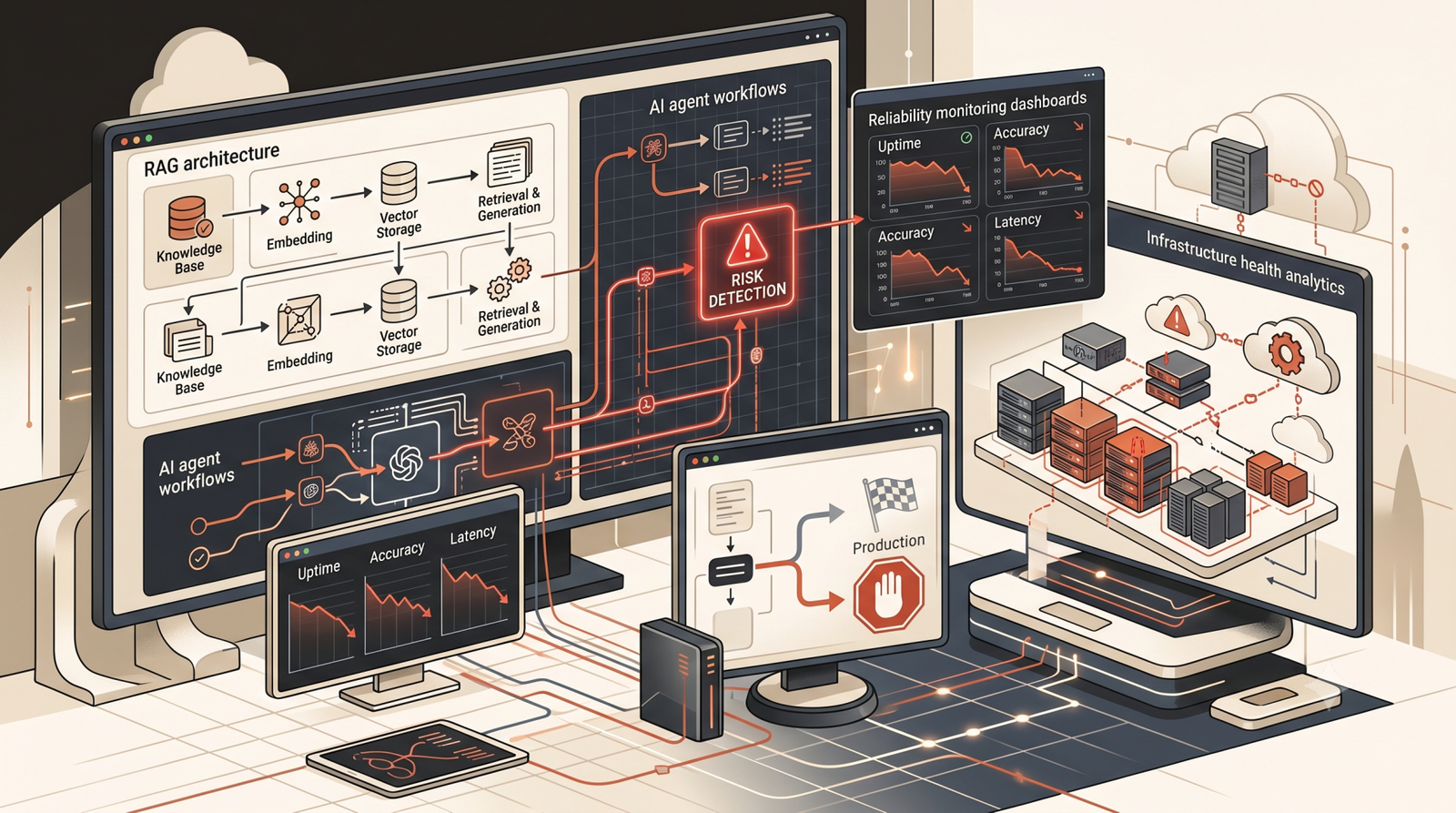
- The Architecture Gap Between Demos and Production
- Why AI Agents Introduce New Operational Risks
- The Hidden Cost Problem
- The Reliability Engineering Layer Most Teams Ignore
- The Organizations Succeeding With Enterprise AI
- Strategic Implications for CTOs and Founders
- Conclusion
The Enterprise AI Gold Rush Has Entered Its Reality Phase
Over the past two years, organizations have invested aggressively in AI agents, Retrieval-Augmented Generation (RAG), workflow automation, and large language model integrations. Executive teams approved budgets, engineering leaders launched proof-of-concepts, and vendors promised transformational productivity gains.
Yet a growing pattern has emerged across enterprises: many AI initiatives never successfully transition from demonstration environments to production systems.
The issue is rarely model capability.
Need MVP Development or AI Solutions?
Turn your idea into reality with Acadify. Fast, scalable, and built for enterprise growth.
The issue is production readiness.
Organizations often underestimate the complexity of deploying AI systems inside environments that require security, governance, observability, reliability, compliance, and measurable business outcomes.
The difference between a successful AI deployment and an abandoned pilot is usually found in architecture decisions rather than model selection.
Key Findings From Enterprise AI Deployments
Across industries including financial services, healthcare, logistics, SaaS, and customer operations, several recurring patterns consistently emerge.
- Pilots often succeed while production deployments struggle.
- Hallucination risk becomes unacceptable at scale.
- Data quality limitations reduce model effectiveness.
- Organizations underestimate operational costs.
- Governance requirements arrive later than expected.
- Monitoring and evaluation frameworks are frequently missing.
- Infrastructure complexity grows rapidly after launch.
Many organizations discover that achieving reliable AI performance is fundamentally different from demonstrating AI capability.
The Most Common Failure Point: Treating AI as a Feature Instead of a System
Traditional software engineering focuses on deterministic outcomes. AI systems operate probabilistically.
This distinction creates significant operational challenges.
Many teams integrate an LLM API, build a user interface, and assume the project is nearly complete. In reality, model integration often represents less than 20% of the total production workload.
Production AI systems require:
- Evaluation pipelines
- Prompt versioning
- Behavior monitoring
- Guardrails
- Security controls
- Fallback mechanisms
- Human review workflows
- Audit logging
- Cost monitoring
- Continuous testing
Organizations that neglect these layers frequently encounter reliability issues shortly after launch.
The Architecture Gap Between Demos and Production
A successful demonstration typically involves:
- One model
- Clean data
- Limited user load
- Short evaluation cycles
A production system must handle:
- Thousands of concurrent requests
- Complex permissions
- Sensitive enterprise data
- Model failures
- Data drift
- Regulatory requirements
- Performance expectations
- Cost constraints
The resulting architecture often includes PostgreSQL, PGVector, Redis, Kubernetes, API gateways, observability platforms, evaluation pipelines, workflow orchestration engines, and security enforcement layers.
The complexity expands far beyond the language model itself.
Why AI Agents Introduce New Operational Risks
AI agents promise autonomous execution across workflows such as customer support, internal operations, document processing, software delivery, and business intelligence.
However, agentic systems introduce additional challenges:
- Tool misuse
- Permission escalation risks
- Unexpected decision paths
- Prompt injection vulnerabilities
- Third-party dependency failures
- Workflow instability
- Data leakage concerns
As autonomy increases, governance requirements increase proportionally.
The organizations achieving the highest success rates are implementing layered approval systems, human oversight checkpoints, and detailed audit mechanisms before expanding agent capabilities.
The Hidden Cost Problem
Many AI business cases focus exclusively on API costs.
Actual production expenses typically include:
- Cloud infrastructure
- Vector databases
- Data pipelines
- Observability platforms
- Evaluation infrastructure
- Security tooling
- Reliability testing
- Human review workflows
- Engineering maintenance
Organizations that model total ownership costs early make significantly better architectural decisions and avoid expensive redesign cycles.
The Reliability Engineering Layer Most Teams Ignore
Reliability has become the defining characteristic separating successful AI deployments from failed initiatives.
Modern AI reliability engineering focuses on:
- Hallucination detection
- Behavioral drift monitoring
- Regression testing
- Prompt evaluation
- Response consistency analysis
- Groundedness validation
- Security testing
- Adversarial simulations
Leading organizations increasingly operate dedicated AI evaluation environments before deploying changes into production systems.
This mirrors the evolution of traditional software quality assurance practices over the last two decades.
The Organizations Succeeding With Enterprise AI
The highest-performing organizations share several characteristics.
- They start with measurable business outcomes.
- They build governance frameworks early.
- They invest heavily in evaluation systems.
- They treat AI as infrastructure rather than a feature.
- They prioritize reliability before scale.
- They continuously monitor production behavior.
- They establish clear ownership models.
Rather than asking, "Which model should we use?" successful teams ask, "How do we operate this system safely and reliably for the next three years?"
Strategic Implications for CTOs and Founders
The next phase of enterprise AI adoption will not be defined by larger models.
It will be defined by operational excellence.
Competitive advantages will increasingly emerge from:
- Evaluation infrastructure
- Reliability engineering
- Governance frameworks
- AI observability
- Data quality systems
- Scalable architectures
- Cross-functional operational processes
Organizations that build these capabilities today will be positioned to deploy increasingly autonomous systems with lower risk and higher business impact.
Conclusion
The future belongs to organizations that understand a critical reality: successful AI implementation is not primarily an AI problem. It is an engineering, governance, operations, and reliability problem.
The enterprises creating sustainable value from AI are not necessarily using the most advanced models. They are building the most resilient systems around those models.
As AI adoption accelerates, production readiness will become the defining differentiator between experimentation and competitive advantage.


No comments yet. Be the first to share your thoughts!